Sometime in the next day or two, Scienceblogs will shut down. We've enjoyed the opportunity to blog here for the past 10+ years. Not to worry, @digitalbio and @finchtalk will continue blogging, but more so from their own site at Digital World Biology. The Scienceblogs posts have been reposted at Digital World Biology's scienceblog archive, and new posts will be at Discovering Biology in a Digital World, now at Digital World Biology.
Enjoy
@digitalbio, @finchtalk

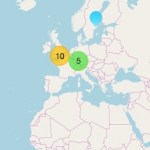
@synbiobeta concluded it’s #sbbsf17 annual meeting on synthetic biology Oct 5, 2017. The progress companies are making in harnessing biology as a platform for manufacturing and problem solving is world changing.
Locations of Synbio Companies
What is Synthetic Biology?
Synthetic biology is a term that is used to describe the convergence of biotechnology and engineering. The dramatic cost decreases in our ability to read and write DNA (sequence and synthesize), combined with increasing capabilities in automation and informatics has catalyzed a new sub-industry within biotechnology. Synthetic…

The biotechnology (biotech) industry is incredibly diverse. Recently, I wrote about the size of the biotech industry, which is, of course, related to how biotechnology is defined. As a strict definition, biotechnology is the use of biology to turn raw materials into useful products. However, the act of developing a biotech product requires many enabling technologies, reagents, and services that form today's modern industry.
The term biotechnology was first coined in 1919 by Károly Ereky, a Hungarian agricultural engineer, who foresaw a time when biology could be used for turning…
A simple web search says biotech is really big. One estimate indicates that the industry will have $400 billion in sales in 2017 with growth to over $775 billion by 2024 [1]. Another report suggests there are over 77,000 employers [2]. That’s big, but is it real, and what you can do with this information?
Worldwide locations of biotechnology employers. Source Biotech-Careers.org
At Biotech-Careers.org we're interested in helping students and graduates of biotech programs at community and four-year colleges learn about the multitude of opportunities available in the…
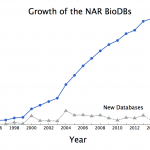
It's time for the annual blog about the annual Nucleic Acids Research (NAR) database issue. This is the 24th database issue for NAR and the seventh blog for @finchtalk. Like most years I have no idea what I'm going to write about until I start reading the new issue. Something always inspires me.
This year's inspiration came from missing data.
In 2017, NAR lists 1662 databases or 23 fewer than last year.
As summarized in the database issue's introduction, Galperin, Fernández-Suarez, and Rigden tell us this year's issue has 152 papers. 54 of those describe new databases, 98…
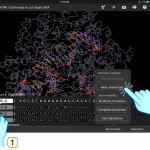
On Sept. 30th, I'm going to be co-presenting a Bio-Link webinar on Genome Engineering with CRISPR-Cas9 with Dr. Thomas Tubon from Madison College. If you're interested, Register here. Since my part will be to help our audience understand the basics of this system, I prepared a short tutorial with Molecule World . Enjoy!
A Quick CRISPR Tutorial
Go to the Digital World Biology CRISPR Structure Collection.
Download the second item in the list, 5F9R, by clicking the link in the Download structure column.
Identify the three components of the CRISPR - Cas system: …
Computers, biological data (molecular sequences, structures, and other data), websites, and databases are integral to modern research. Innovations like precision, or personalized medicine, expect a certain level of patient participation, and our future food and environmental sustainability will require that society can access a multitude of computer-based resources. Thus, higher education has an important role in providing students with employable skills as well as the ability to use data to make important personal and societal decisions. Toward that goal it is worthwhile understanding…
It's well understood in science education that students are more engaged when they work on problems that matter. Right now, Zika virus matters. Zika is a very scary problem that matters a great deal to anyone who might want to start a family and greatly concerns my students.
I teach a bioinformatics course where students use computational tools to research biology. Since my students are learning how to use tools that can be applied to this problem, I decided to have them apply their new bioinformatics skills to identify drugs that work against Zika…
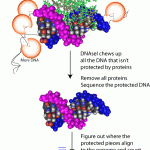
Did you know small fragments of DNA are circulating in your blood stream?
These short pieces of DNA are left behind after cells self-destruct. This self-destruction, or apoptosis, is a normal process. In the case of fetal development, certain cells in our hands die, leaving behind individual fingers. Immune system cells leave traces of DNA behind after they’ve tackled invading microbes. DNA can also appear in the blood when people have cancer.
I had the good fortune, last Monday, to hear Matthew Snyder describe this cell-free DNA in a fascinating talk and learn why DNA in the blood can be a…
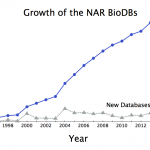
Someone missed the memo. Over the past year, news and presentations by NIH leaders like Philip Bourne have communicated that the proliferation biologically focused databases is unsustainable. However, unlike last year, where the number of databases tracked by Nucleic Acids Research (NAR) dropped by three databases, 2015's net growth was 136.
Counting databases is hard
As summarized in the database issue's introduction, Rigden, Fernández-Suarez, and Galperin tell us this year's issue (the 23rd annual) has 178 papers. 62 papers describe new databases, 95 provide…

"By night all cats are gray" - Miguel Cervantes in Don Quixote
I've always liked Siamese cats. Students do, too. "Why Siamese cats wear masks" is always a favorite story in genetics class. So, when I opened my January copy of The Science Teacher, I was thrilled to see an article on Siamese cat colors and proteins AND molecular genetics (1).
In the article, the authors (Todd and Kenyon) provide some background information on the enzymatic activity of tyrosinase and compare it to the catechol oxidase that causes fruit to brown, especially apples.…
Imagine a simple hike in a grassy part of South America. You hear a rattle and feel a quick stab of pain as fangs sink into your leg. Toxins in the snake venom travel through your blood vessels and penetrate your skin. If the snake is a South American rattlesnake, Crotalus terrific duressis, one of those toxins will be a phospholipase. Phospholipases attack cell and mitochondrial membranes destroying nerve and muscle function. Without quick treatment, a snakebite victim may be die or suffer permanent damage (1, 2).
The phospholipase from…
When finding a female scientists' data turns into an archeological treasure hunt.
A few months ago, I decided it would be interesting to celebrate various scientific contributions by making images of chemical / molecular structures in the Molecule World iPad app and posting them on Twitter (@MoleculeWorld). Whenever I can, I like to highlight scientific contributions from women on their birthdays. Tomorrow's post will feature Dr. Isabella Karle, an x-ray crystallographer who worked on the Manhattan project and solved structures of interesting molecules like…
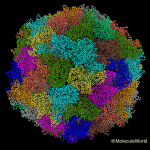
When my parents were young, summer made cities a scary place for young families. My mother tells me children were often sent away from their homes to relatives in the country, if possible, and swimming pools were definitely off limits. The disease they feared, poliomyelitis, and the havoc it wrecked were the stuff of nightmares. Children could wake up with a headache and end up a few hours later, in an iron lung, struggling to breathe.
Poliovirus colored by molecule in Molecule World.
…
We've been fans of the Molecule of the Month series by David Goodsell, for many years. Not only is Dr. Goodsell a talented artist but he writes very clear descriptions of the ways molecules like proteins, RNA, and DNA work together and function inside a cell.
To learn about proteins and their activities, I like to go directly to the Molecule of the Month page, where I can find a list of articles organized by molecule type and name. Many of these articles can also be downloaded in a PDF format.
A really nice of his articles is that he includes PDB IDs for all the…
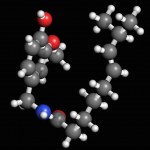
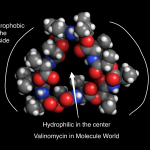
To have an effect, a molecule must bind to a receptor and trigger a signal. Studying a receptor's structure can give us insights about the way this triggering process works.
Capsaicin is a fascinating molecule that puts the "pep" into peppers. Curiously, the amount of capsaicin in a pepper is measured with a test devised in 1912 by Wilbur Scoville. Dried peppers are dissolved in alcohol, this liquid extract is diluted in water, and trained people determine the pepper's Scoville value by "tasting" the heat.
I wonder how these people are recruited.…
National DNA Day has a fun challenge for teachers and classrooms using Pinterest. Your class can join a larger, national, effort to create a National DNA Day Pinterest board by making your own class Pinterest board on DNA, genetics, and genomics. Some possible topics are:
Things to do with DNA
DNA and health
DNA and the Arts
DNA in the News
We're really excited about the topic on DNA and the Arts!
Here's how you can make some lovely DNA Art images for your Pinterest board in Molecule World on an iPad or, if you don't have access to an iPad, you can use Cn3D…
Something interesting happened in 2014. The total number of databases that Nucleic Acids Research (NAR) tracks dropped by three databases!
What happened? Did people quit making databases? No. This year, the "dead" databases (links no longer valid) outnumber the new ones. To celebrate Digital World Biology's release of Molecule World I'll discuss some of the new structure databases below. But first, the numbers.
As summarized in the database issue's introduction, Galperin, Rigden, and Fernández-Suárez tell us this year's issue has 172 papers. 56 of those…
Pull a spaghetti noodle out of a box of pasta and take a look. It's long and stiff. Try to bend it and it breaks. But fresh pasta is pliable. It can fold just like cooked noodles.
When students first look at an amino acid sequence, a long string of confusing letters, they often think those letters are part of a chain like an uncooked spaghetti noodle. Stiff and unbending, with one end far from the other.
Molecular modeling apps let us demonstrate that proteins are a bit more like fresh pasta.
If we apply rainbow colors (Red Orange Yellow Blue…
Sometimes when you go digging through the databases, you find unexpected things.
When I was researching the previous posts on insulin structure and insulin evolution, I found something curious indeed.
Human insulin, colored by rainbow. Image from the Molecule World iPad app by Digital World Biology.
I wanted to find out how many different organisms made insulin, so I used a database at the NCBI called Blink. Blink is a database of protein blast search results. Using Blink can save you lots of time because…