sequence analysis
A few weeks back, we published a review about the development and role of the human reference genome. A key point of the reference genome is that it is not a single sequence. Instead it is an assembly of consensus sequences that are designed to deal with variation in the human population and uncertainty in the data. The reference is a map and like a geographical maps evolves though increased understanding over time.
From the Wiley On Line site:
Abstract
Genome maps, like geographical maps, need to be interpreted carefully. Although maps are essential to exploration and navigation they…
In our series on why $1000 genomes cost $2000, I raised the issue that the $1000 genome is a value based on simplistic calculations that do not account for the costs of confirming the results. Next, I discussed how errors are a natural occurrence of the many processing steps required to sequence DNA and why results need to be verified. In this and follow-on posts, I will discuss the four ways (oversampling, technical replicates, biological replicates, and cross-platform replicates) that results can be verified as recommended by Robasky et. al. [1].
The game Telephone teaches us how a…
I had the good fortune on Thursday to hear a fascinating talk on deep transcriptome analysis by Chris Mason, Assistant Professor, at the Institute for Computational Biomedicine at
Cornell University.
Several intriguing observations were presented during the talk. I'll present the key points first and then discuss the data.
These data concern the human transcriptome, and at least some of the results are supported by follow on studies with data from the pigmy tailed macaque.
Some of the most interesting points from Mason's talk were:
A large fraction of the existing genome…
These days, DNA sequencing happens in one of three ways.
In the early days of DNA sequencing (like the 80's), labs prepared their own samples, sequenced those samples, and analyzed their results. Some labs still do this.
Then, in the 90's, genome centers came along. Genome centers are like giant factories that manufacture sequence data. They have buildings, dedicated staff, and professional bioinformaticians who write programs and work with other factory members to get the data entered, analyzed, and shipped out to the databases. (You can learn more about this and go on a virtual tour in this…
You might think the coolest thing about the Next Generation DNA Sequencing technologies is that we can use them to sequence long-dead mammoths, entire populations of microbes, or bits of bone from Neanderthals.
But you would be wrong.
Sure, those are all cool things to do, but Next Generation DNA sequencing (or NGS for short) can give us answers to questions that are far, far more interesting.
With NGS, we can look at entire transcriptomes (!!) together with the proteins that make them and the DNA modifications that help regulate them. If we compare a cell to music, a genome sequence…
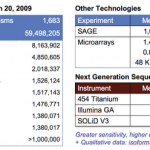
Last spring, I gave my first hands-on workshop in working with Next Generation Sequencing data at the Eighth Annual UT-ORNL-KBRIN Bioinformatics Summit at Fall Creek Falls State Park in Tennessee. The proceedings from that conference are now on-line at BMC Bioinformatics and it's fun to look back and reflect on all that I learned at the conference and all that's happened since.
Figure 1. Fall Creek Falls State Park, TN
When the conference took place, Geospiza had only just released new versions of GeneSifter Analysis Edition that could do gene expression analysis with Next Gen data.
Who…
No more delays! BLAST away!
Time to blast. Let's see what it means for sequences to be similar.
First, we'll plan our experiment. When I think about digital biology experiments, I organize the steps in the following way:
A. Defining the question
B. Making the data sets
C. Analyzing the data sets
D. Interpreting the results
I'm going intersperse my results with a few instructions so you can repeat the things that I've done…
We'll have a blast, I promise! But there's one little thing we need to discuss first...
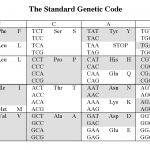
I want to explain why I'm going to use nucleotide sequences for the blast search. (I used protein the other day). It's not just because someone told me too, there is a solid rational reason for this.
The reason is the redundancy in the genetic code.
Okay, that probably didn't make any sense to those of you who didn't already know the answer. Here it is.
The picture above shows the human genetic code (there are at least 16 variations on this, but that's another story). Each middle cell in the…
We had a great discussion in the comments yesterday after I published my NJ trees from some of the flu sequences.
If I list all the wonderful pieces of advice that readers shared, I wouldn't have any time to do the searches, but there are a few that I want to mention before getting down to work and posting my BLAST results.
Here were some of the great suggestions and pieces of advice;
1. Do a BLAST search. Right! I can't believe I didn't do that first thing, I think the trees I got surprised me so much all sense flew out of my brain.
2. Show us the multiple alignments. Okay. I'll…
What tells us that this new form of H1N1 is swine flu and not regular old human flu or avian flu?
If we had a lab, we might use antibodies, but when you're a digital biologist, you use a computer.
Activity 4. Picking influenza sequences and comparing them with phylogenetic trees
We can get the genome sequences, piece by piece, as I described in earlier, but the NCBI has other tools that are useful, too.
The Influenza Virus Resource will let us pick sequences, align them, and make trees so we can quickly compare the sequences to each other.
This is how I got the sequences that I wrote about…
This afternoon, I was working on educational activities and suddenly realized that the H1N1 strain that caused the California outbreak might be the same strain that caused an outbreak in 2007 at an Ohio country fair.
UPDATE: I'm not so certain anymore that the strains are the same. I'm doing some work with nucleic acid sequences to look further at similarity.
Here's the data.
Once I realized that the genome sequences from the H1N1 swine flu were in the NCBI's virus genome resources database, I had to take a look.
And, like eating potato chips, making phylogenetic trees is a little bit…

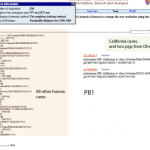
I was pretty impressed to find the swine flu genome sequences, from the cases in California and Texas, already for viewing at the NCBI.
You can get them and work them, too. It's pretty easy. Tomorrow, we'll align sequences and make trees.
Activity 3: Getting the swine flu sequence data
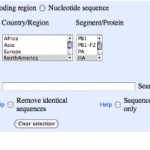
1. Go to the NCBI, find the Influenza Virus Resource page and follow the link to:
04/27/2009: Newest swine influenza A (H1N1) sequences.
2. You'll see a page that looks like this:
Each column heading is a name of a segment of the influenza genome. You can see there are eight of these. Each segment…

Genome sequences from California and Texas isolates of the H1N1 swine flu are already available for exploration at the NCBI. Let's do a bit of digital biology and see what we can learn.
Activity 1. What kinds of animals get the flu?
For the past few years we've been worrying about avian (bird). Now, we're hearing about swine (pig) flu.
All of this news might you wonder just who gets the flu besides pigs, birds, and humans. We can find out by looking at the data.
Over the past few years, researchers have been sequencing influenza genomes and depositing those genomes in public…
Watching the chIPs roll in,
then I watch them roll away again,
I'm just sitting on the DNA,
wasting time
(sung to the tune of "Sitting on the dock of the bay" by Otis Redding)
Hesselberth et.al. recently published a paper about digital genomic
footprinting that blew me away because it has so much potential. The authors used DNAse I and Next Generation DNA Sequencing to map every site in the yeast genome where a protein might be sitting.
Since I used to do similar kinds of experiments, albeit on a much, much smaller scale, this sort of publication boggles my mind. It's only recently that I've…
In which we identify unknown human proteins.
Yesterday, I wrote about using the BLOSUM 62 matrix to calculate a score for matches between two proteins. Those scores give us a good start on understanding how blastp determines whether two sequences are matching by chance or because they're more likely to be related. But that's not all there is to calculating a blast score, and there's at least one other statistic to consider as well, the E value.
It all comes down to biochemistry
The BLOSUM 62 matrix is based on the substitutions that really do or do not happen in real protein sequences. I…
In which we search for Elvis, using blastp, and find out how old we would have to be to see Elvis in a Las Vegas club.
Introduction
Once you're acquainted with proteins, amino acids, and the kinds of bonds that hold proteins together, we can talk about using this information to evaluate the similarity between protein sequences. We can easily imagine that if two protein sequences are identical, then those proteins would have the same kind of activity. But what about proteins that are similar in some regions, and not others, or proteins that only share some of the same amino acids in similar…
Ebola virus has impressed me as creepy ever since I read "The Hot Zone: A Terrifying True Story some years back by Richard Preston. (I guess he has a new book, too, Panic in Level 4: Cannibals, Killer Viruses, and Other Journeys to the Edge of Science but I haven't been in airport for the past couple of weeks, so I haven't read it yet.)
Technorati Tags: blast, phylogenetic trees, Ebola, viruses
Infectious agents that cause diseases with gruesome symptoms really excite those of us with an interest in microbiology. Tara has written about this paper, too, and summarized the details.
I…
One of the holy grails of modern medicine is the development of a vaccine against HIV, the virus that causes AIDs. An obstacle to attaining this goal has been the difficulty in stimulating the immune system to make it produce the right kinds of antibodies. A recent finding in Science describes a gene that controls production of these antibodies and may provide insights to the development of an effective vaccine. (1).
Antibodies are special kinds of proteins that bind to things, often very tightly. If they bind to the right molecules, they can prevent viruses from infecting cells and target…
Let's play anomaly!
Most of this week, I've written about the fun time I had playing around with NCBI's Blink database and finding evidence that at least one mosquito, Aedes aegypti, seems to have been infected at some point with a plant paramyxovirus and that the paramyxovirus left one of its genes behind, stuck in the mosquito genome.
During this process, I realized that the method I used works with other viruses, too. I tried it with a few random viruses and sure enough, I found some interesting things.
You've got a week to give it a try. Let's see what you find! The method is…
Lots of bloggers in the DNA network have been busy these past few days writing about Google's co-founder Sergey Brin, his blog, his wife's company (23andme), and his mutation in the LRRK2 gene.
I was a little surprised to see that while other bloggers (here, here, here, and here) have been arguing about whether or not the mutation really increases the risk to the degree (20-80%) mentioned by Brin, no one has really looked into the structure and biochemistry of the LRRK2 protein to see if there's a biochemical explanation for Parkinson's risk. I guess that task is up to me.
Let's begin at…