
Michael Nielsen gets it right, again.
This is what I'm on about when I talk about ontologies and object-orientation of knowledge. In science, the code is the knowledge. Unlike computer programming, the code is locked up PDF and XML formats, and behind firewalls and copyrights (at least in code you could write your own if you knew what you wanted.). On top of that, ontologies are a royal pain in the ass.
But it's worth it - if the pain is big enough. Standard ontologies and common names mean we at lest get a speck of modularity in database aggregation, for example. You can do some cool stuff…
After Science Commons hit the reddit heights earlier this year, I started talking to Alexis Ohanion about how we could start to work together. We are still scheming. But in the interim, he's launched a cool and inventive way to raise a little cash for Science Commons.
In the goal of creating the ultimate meme-launching organism, the folks at breadpig (including a great quote by CC alum Tim Hwang) have announced ROFLDNA - based the DNA of internet celebrities as varied as MC Frontalot and my own personal favorite, the Tron Guy. Their DNA has been combined and turned into a Mini DNA portrait by…
I don't like getting into blog back and forths, but this post from the Information Research folks really deserves a reply of its own. I believe this is an honest piece of confusion, and it's likely the result of FUD from the traditional publishing community. I invite the Information Research folks to contact me if they have questions about how Open Access works from a legal perspective so that we can counter any unwarranted fears about how to make the sharing involved easy and legal - we're here to help.
From the post:
If the author retains copyright, as Information Research authors do, it is…
Big FriendFeed chatter on the interwebs yesterday about JoVE "moving" to a closed access model.
This is being covered extensively on the FF conversation so I won't dredge through the points there - if you want to see the arguing and JoVE responses, head over there.
What's interesting for me is the lack of conversation about the importance of licensing. There is a reason Open Access talks about copyrights in the definitions. Let's go back and remember:
By "open access" to this literature, we mean its free availability on the public internet, permitting any users to read, download, copy,…
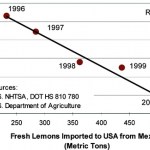
No, this is not an April Fool's post.
I found the argument about mexican lemons at Derek Lowe's In the Pipeline (if you've not got it on your RSS aggregator, get thee behind me) and thought it was a better way to celebrate the day of fools than by doing something fake like "I'm going to work at Elsevier as head of intellectual property!" or some such.
You see, we get fooled all the time by data. And frequently we really, really want the data to tell us something specific - something we've been looking for, for a very long time. Or we want to have the data tell us something coherent - to tell…
I gave a talk at eTech two weeks ago. It was a busy time - I was in the middle of my wedding, which was in Brazil, and I actually had to leave Brazil and fly to San Jose to give the talk, have a couple of meetings, and fly right back so that I could rejoin the wedding festivities. We were announcing a collaboration with Microsoft (which has garnered its own attention and criticism, and deserves its own blog posting here, which it will get) as well.
I'm also trying out some new themes for talks. I gave over 70 talks last year and although I loved the three core talks I gave much of the year,…
I am just back from my wedding and have a lot of catching up to do - notably I will respond to the eTech announcement of the Science Commons collaboration with Microsoft, and the small furor that my comment "there is no crowd" in science has caused.
But first things first. I'm a day late posting but I wanted to make sure I got this in.
Ada Lovelace Day is an international day of blogging to draw attention to women excelling in technology.
We are asked to blog about a female role model for us in technology. Mine's pretty easy.
Diane Cabell.
When I was a wet behind the ears kid masquerading as…
Big news today at the CHI Medicine Tri-Conference. Merck has pledged to donate a remarkable resource to the commons - a vast database of highly consistent data about the biology of disease, as well as software tools and other resources to use it. The resources come out of work done at the Rosetta branch of Merck (you might remember them as the company whose sale capped a boom in bioinformatics) and is at its root a network biology system. In use inside Rosetta/Merck last year alone it led directly to a ton of publications.
This is all going to happen through the establishment of a non-profit…
Sorry for the long delay between posts. I was robbed at the beginning of the month, losing my laptop, passport, other pieces of digital technology and identification, house keys, work keys, pens, papers, business cards and so forth. I'm just now catching up with all the real-life work that piled up during the seven-days-without-a-computer phase.
I have some posts queued up, trying to finish out the lengthy series on copyright and databases. And I am going to try to write something approaching a final summary on why I don't like licensing as an approach for databases, instead preferring the…
Science Commons got picked up on reddit this week. It was surreal - we hit the top of the charts for about 24 hours, got way more web traffic than usual, and the SC/Dylan video got almost 4000 views. Wacky.
And now our logo's embedded on the reddit logo on the home page.
This is neat. We've spent years toiling away at Science Commons and save one or two articles, mainly which tend to focus on me personally, we don't get a lot of attention. I was surprised and gratified to see this happen, organically, from a lot of folks who I wouldn't have expected to give a hoot about us.
I'll address a…
In the first post, I talked about how factual data aren't creative works, and how compiling them into collections doesn't make them creative - at least in the US.
This aspect of data rips away the core "incentive" provided by copyright law to creators: the right to sue people who make copies. It also has a second aspect, which is that the international treaties that govern copyright don't apply. Whatever one may think of those treaties, they do a fair amount to normalize the laws worldwide - a copyright on a Britney Spears tune applies in much the same way in wildly different countries. For…
I got drawn into a debate about copyrights and factual data this week that felt like it merited its own blog post. It was kind of surreal new media debating - I was going back and forth with a smart guy from the UC Berkeley school of information on a friend's Facebook wall for most of a day on the topic. It was definitely a change from the typical FB chatter and in some ways the character count constraints of a wall post were formative to the debate. But some of the questions raised deserved long answers, and the issues involved are complicated and subtle and non-obvious. Hopefully moving the…
Gerry Bayne of Educause interviewed me in December as part of the Coalition for Networked Information annual meeting. It's available in excerpts as part of the Educause Now monthly podcast and in full as a standalone cast.
It's always a little hard to explain this stuff, but Gerry's done a good job (in my admittedly biases opinion) at extracting the story, especially in the educause now editing...
I've been working on some text for a series of papers lately. I'm writing the core of a book proposal and working through the ideas around the knowledge web and the knowledge economy, and thought I'd post some interim thoughts here.
Knowledge is a funny thing. Philosophers have spent eons debating it. I'm not going to figure it out here - in fact, the conclusion that I wasn't going to figure it out played a big role in my choosing not to go to graduate school. But on the web, we have these things that are kind-of-knowledge. Databases. Journal articles. Web pages. Ontologies.
Taken together…
Added to the Japanese version I blogged about recently, the SC video with Jesse Dylan has been subtitled into Spanish. Found via userbarna.net.
Keita Bando Mr. Komada has translated the SC video done by Jesse Dylan into Japanese. Keita told me about this and has used the service dotsub to add the subtitles to the video directly.
See what happens when you empower users?
(of course, if he's given us the slip like that Max Planck journal who published a brothel ad on their cover, consider me fooled!)
Spent the morning at the American Geophysical Union annual meeting. It is a massive affair, right across the street from another big one (American Society of Cell Biology, which I've also spoken at in years past...). The area around Moscone is filled with dazed science geeks wearing nametags; I spent a few minutes dreaming of a jets-v-sharks thing between a bunch of tissue culture technicians and the international polar year team.
I spoke on the usual stuff: legal, normative, and social issues around data sharing. It was a little odd this time though - I was preceded and followed by people…
From the Independent:
A respected research institute wanted Chinese classical texts to adorn its journal, something beautiful and elegant, to illustrate a special report on China. Instead, it got a racy flyer extolling the lusty details of stripping housewives in a brothel.
Let me be the first to make the joke that I'm all for "open access" but this is a bit much...nyuk nyuk nyuk...
I gave a project briefing yesterday at the CNI fall meeting. I talked about our experience in building the Neurocommons project and the release of our RDF distribution for data integration in molecular biology.
The meeting was PACKED. 400+ people. I was sad that my briefing was up against the OAI-ORE briefing - that's a project we want to connect to at a deep level - but I was glad to have a good crowd. It's a little intimidating to get questions from Don Lindberg about your use of bio-information from the National Library of Medicine, or from George Strawn about the NSF use of semantics.
One of the hardest parts of the day job is trying to explain why the commons works for science to people. I find that I have to start by explaining what science actually is, how science works, and how that doesn't take advantage of the possibility of the internet, which means I have to explain the possibility of the internet, and on and on. The smarter the non-scientist, ironically, the harder this can be - because the smart non-scientist frequently has a hard opinion about science and the internet. "Just get it online and everything will be fine!" is a common refrain.
Several months ago, I…